Posted by Lawpig on 6月 04, 2017 | No comments
從LLVM談 Portable Native Client Software Fault Isolation技術
從LLVM談 Portable Native Client Software Fault Isolation技術
by loda
有次在閱讀文章時,看到這段話 「不,知識是有限的,只有愚蠢才是無限的。」by 叔本華(十九世紀 德國哲學家),當下會心一笑,也覺得若我們認為自己無所不知,那可能就正好落入愚蠢的陷阱了…:^o^
會對SFI技術有興趣的主因在於,過去所認為的安全機制確保,不外乎就是透過User/Kernel Mode基於處理器的機制,把UnTrust Code的部分區隔出來,或像是透過Virtualization技術,以虛擬機環境實現同樣的目的.然而在接觸到LLVM與Google的Native Client技術後,才發現其實這條路上還有很多種可能,如果不是參考到這些作法,自己並不知道原來還可以有這樣的方案誕生. 也因此希望可以把這技術推廣給更多人知道,若能對各位有些許幫助,該當是最棒的事情了.
Google在瀏覽器上推廣Native Client技術,希望藉此讓Browser應用可以達到Native應用程式的效能.而Native Client之所以可以達到這樣的目標,正是因為他可以讓Browser執行Native Code,但若僅僅如此,那層出不窮的安全問題,將成為這方案最大的罩門.也因此,SFI技術成為Google在瀏覽器上運行Native Code的安全防護機制,透過Inner/Outer Sandbox機制,讓在瀏覽器中運行的Native應用程式雖然可以直接以處理器指令運行程式,但卻被限制在Google Sandbox所預設的行為範疇中.
既然SFI解決了Native Client亟需的安全問題,另一個能讓Native Client普及的利器就是LLVM,沒有LLVM之前的Native Client只能在x86 32/64bits環境下執行,對於目前以ARM為主的手持裝置來說,無疑就有推廣上的困難,也因此Google將LLVM的跨平台特性與Native Client進行結合,發展了名為Portable Native Client的新技術,讓基於LLVM所開發的BitCode可以透過瀏覽器下載到不同的平台上,再藉由PNaCl Translate技術,把BitCode根據不同平台的差異轉為適應於該平台的Native Code,並藉由原本的Native Client SFI 技術,確保既有跨平台的特性,又兼顧潛在的安全問題.
目前的Portable Native Client 可支援 ARM ,x86 32/64bits平台,藉此可橫跨一般的電腦與智慧型手機的應用.
參考下圖所示,除了Native Client會以Portable Native Client的技術來將LLVM應用到Browser的世界外,在Android手機上,包括原生的C/C++ Native應用程式,Dalvik Java ByteCode或是Render Script都可以基於LLVM技術,以BitCode的形式編譯後,在根據不同目標平台的差異,以便Translate成為目標平台最佳化後的指令集,也就是說當Android與Browser Native Client逐步普及,可預見的未來LLVM技術將會成為影響我們網際網路與手持設備應用的重要核心技術.

有關Portable NaCl SFI 技術,以下兩篇Paper是Google所發佈的論文,也非常有參考的價值,有興趣的開發者,可自行參閱
1,Native Client: A Sandbox for Portable, Untrusted x86 Native Code (In the 2009 IEEE Symposium on Security and Privacy,http://research.google.com/pubs/pub34913.html)
2,Adapting Software Fault Isolation to Contemporary CPU Architectures (Publication Year 2010,http://research.google.com/pubs/pub35649.html)
目前有關 3rd-party Native Code安全執行的設計方案,主要有
1,Fault-Isolation: 這是本文Native Client SFI所基於的概念,但基於平台的差異,還可以有所調整,例如x86 CISC指令集,可以透過Code/Data Segment Register去限制應用程式可以存取或執行的記憶體範圍,而這樣基於CISC架構的實作就稱為CFI(CISC Fault Isolation),但這樣的機制由於也利用到了x86處理器的Segment Register特性,也因此如果要應用到RISC平台,像是ARM方案時,就會有所局限性 (ARM並沒有 Segment Register).反之目前Google所採用的SFI則可無需被特定平台限制住.
2,Trust with Authentication: 這是微軟ActiveX的作法,主要缺點為所信賴的基礎為憑證,若是沒有憑證則會跳出警告,由使用者決定安裝與否.但實際上使用者並沒有能力決定哪個軟體或應用是安全無虞的,且過多的警告訊息,也讓使用者對於Native Code傳遞到使用者端的行為,有預先認定不安全的認知.
3,System Request Moderation (User-ID based Access Control): Android Application Sandbox應該就是這類實作的最佳案例.以往,在Linux執行環境,會以同一個使用者ID去執行多個應用程式,也因此每個應用程式都是基於同一個使用者ID與權限的保護下,如此的缺點就是當其中有第三方的應用程式會去進行對其它應用程式的不合法行為時,就需另外去設想其它的保護措施. Android Application Sandbox 會讓每個使用者安裝的應用程式有各自的User-ID(也就像是個Linux Kernel-Level Application Sandbox),藉此就可基於Linux Kernel每個User-ID與預設相關系統行為的特權User-ID區分,以達到應用程式的安全保護機制. 屬於第三方應用程式的User-ID,會因此無法去執行需要具備特權等級才能執行的動作或呼叫的System Call.而且由於每個應用程式會在自己所屬的User-ID權限下執行,也可以避免惡意程式對其它應用(User-ID)的不合法修改.
本文重點會放在Native Client的SFI技術,並會把有關的議題逐一說明,希望對有興趣的開發者而言,可以帶來幫助.
Android Portable NaCl 支援檔案類型
參考Google的文件 ‘http://www.chromium.org/nativeclient/pnacl/pnacl-shared-libraries-final-picture ‘, 在Portable NaCl執行環境中,目前支援的檔案類型如下表所示,其中包括跨平台的動態函式庫(Portable SO)與跨平台的執行檔(Portable EXE)..etc
| 副檔名 | 說明 |
| Bitcode (.bc) | 這是原本透過LLVM clang所編譯出來的 BitCode檔案格式,包含執行所需的程式與資料,但沒有PNaCl所需的MetaData.
例如以 clang 編譯所產生的BitCode檔案
clang -O3 -emit-llvm sample.c -c -o sample.bc
可透過指令 llvm-dis 如下所示
llvm-dis sample.bc
把sample.bc反組譯為 sample.ll
並可透過LLI直譯器執行或經由LLC轉譯為目標平台的Assembly
|
| Portable Executable (.pexe) | 這是透過過PNaCl clang 所編譯出來BitCode的Portable Executable檔案格式,並可再根據需求轉譯為目標平台的可執行檔 (.nexe). PEXE檔案格式跟原本的BitCode相比主要多了以下的MetaData內容,
1,用以表明執行檔是靜態連結(加上-static參數編譯)還是有動態載入函式庫需求.
2,會包含這檔案執行時所相依的動態函式庫.SO檔案列表
3,包含Run-Time所需來自外部的Dynamic Symbol Table,會在此記錄Symbol名稱,版本資訊與會透過哪個動態函式庫提供該Symbol
基於PNaCl Clang編譯後,就會把上述的MataData資料置入產生的PEXE檔案中.
例如以 pnacl-clang 編譯所產生BitCode的PEXE檔案格式
pnacl-clang hello.c -o hello.pexe
其實,對一個要下載到瀏覽器執行的NaCl檔案而言,MetaData可以透過網頁下載對應的*.NMF 檔案進行判讀.並可透過指令pnacl-nmf把PEXE檔案中的MetaData讀出,如下所示
pnacl-nmf hello.pexe
|
| Portable Shared Object (.pso) | 這是透過過PNaCl clang 所編譯出來BitCode的Portable Shared Object檔案格式,可再轉譯為.SO動態函式庫檔案格式. 在這個.SO中還會包括以下PNaCl所需的MetaData內容
1, .So檔案與其它.SO檔案的相依性 (例如呼叫其它.SO所提供的函式)
2, 包含Run-Time所需來自外部的Dynamic Symbol Table
操作方式為在編譯過程中在pnacl-clang 工具後加入 -shared 參數.
|
| .pso | 為Portable BitCode Object File,亦可透過pnacl-translate轉成Native的Object File |
| .nexe | 為編譯為Native Code的Native Client 執行檔案格式 |
| .so | 為ELF Native Shared Library檔案格式 |
基於上述 BitCode,PSO,PEXE,NEXE,SO的運作概念,可彙整如下圖所示
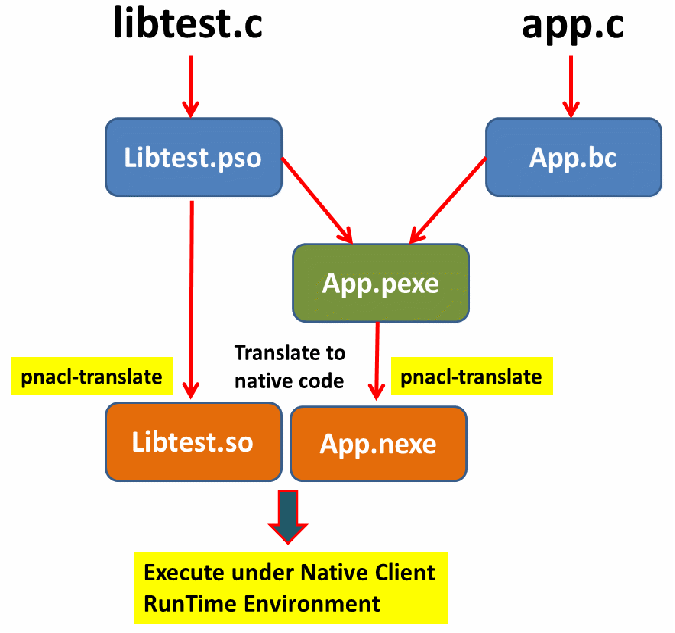
Chrome瀏覽器是目前驗證Native Client的最佳環境,以下將說明如何設定以支援Native Client應用程式.
讓Chrome瀏覽器支援 NaCl 應用下載
參考連結https://developers.google.com/native-client/devguide/devcycle/running 中的說明,以筆者使用的Google Chrome 19.0.1084.56版本來說,可以在瀏覽器中輸入 “about:flags” 字串,就可以看到基於 “chrome://flags/” 的chrome實驗性功能設定選項.

再試著連到支援Native Client的網頁,由於Chrome Web Store上已經有支援Native Client的Web應用程式,因此驗證最簡單的方式就是直接連到 CWS網頁上搜尋Native Client,或直接點選這個連結 https://chrome.google.com/webstore/search/native%20client ,就可以找到能在Chrome瀏覽器執行的Native Client網頁應用了.
CFI (CISC Fault Isolation) 技術介紹
談到CISC Fault Isolation,很直覺會想到同樣基於硬體的保護,最經典的實例應該就是一般作業系統上的User/Kernel Space,讓 UnTrust Code放在User Space,而Trust的Code放到Kernel Space,基於MMU (Memory Management Unit)的保護,User Space如果去存取Kernel Space資料內容就會發生Exception. 而User Space要執行/存取Kernel Space 程式碼/資料時,就會透過System Call,一般來說在x86是透過中斷(Windows為0x2E 與 Linux為 0x80),而在ARM平台上是透過SWI(Software Interrupt).(不只MMU機制,若有其他的硬體保護,也可算是Hardware Fault Isolation.),如下圖所示
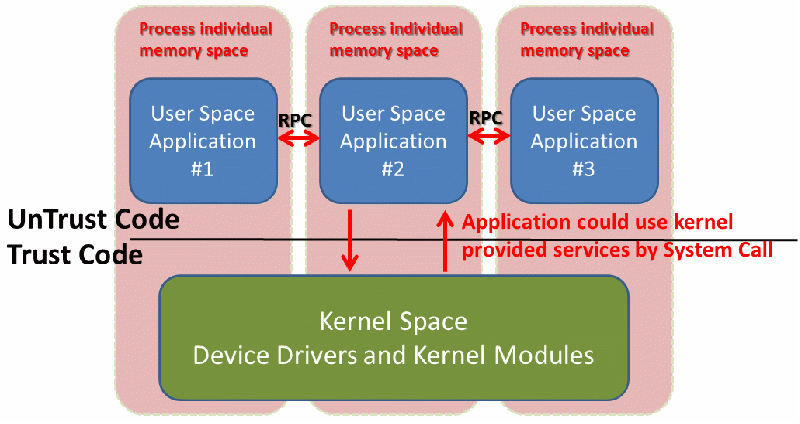
而跨Process間的呼叫,則可透過Socket搭配RPC (Remote Procedure Call),但因為呼叫端與被呼叫端是在兩個不同的Memory Space,由A呼叫B時,還必須要觸發行程的排程,除了Socket/RPC本身成本外,還需要加上被呼叫端B被處理器排程到,與之後回到呼叫端A處理被呼叫端B返回結果的時間成本,也因此相對於同一個Memory Space函式的彼此呼叫,RPC可算是效率相對差的方案.
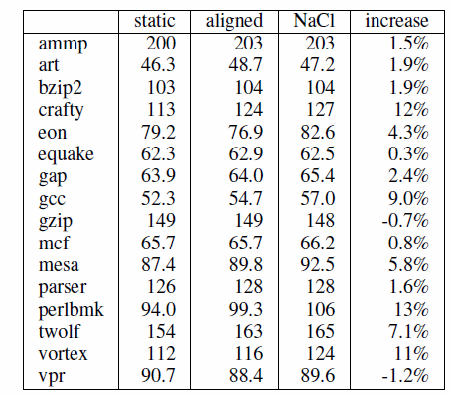
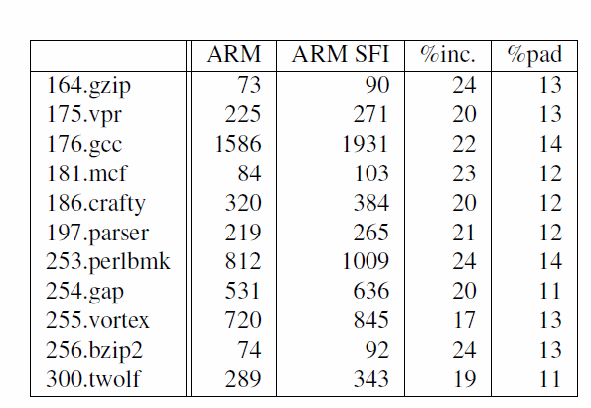
而CFI技術則是在同一個Memory Space下,實現Trust/UnTrust兩個模組間的呼叫.比較CFI與SFI技術的效率差異上,根據Google文件的說明,在開啟NaCl SFI技術對程式碼Control-Flow Memory Integrity的稽核機制下,在 Cortex A9 out-of-order ARM平台上NaCl SFI增加約5% Overhead,而在x86_64平台上增加約7%的執行Overhead.相對於原本基於x86平台的CFI技術 (可參閱下表來自 “Native Client: A Sandbox for Portable, Untrusted x86 Native Code ”論文中的測試數據),可以發現在x86平台上如果是基於硬體支援Segment Register的CFI技術,多數的情況大概都只有2%左右的Overhead.
x86 32bits版本的CISC Fault Isolation方案,主要有以下的特點
1,Code Section為Read-Only Statically Linked.
2,Code Section必須是32bytes Alignment (也就是說每個函式的起點一定是 32bytes Alignment,而函式結尾也一定會Padded到32bytes Alignment.
3,在Code Segment內可被執行到的處理器指令,在啟動時都會經過Native Code檢查程式驗證無虞後才執行.
4,所有非直接的程式碼流程跳躍 (例如要經過暫存器的運算才得到目標記憶體位址),都會被一組指令集所取代,用以確保在Run-Time時,最後所要跳過去執行的Target Address是落在合法的範圍內.
| 10002e7: 83 e1 e0 and $0xffffffe0,%ecx
10002ea: ff e1 jmp *%ecx
|
5,會確保沒有任何處理器指令操作,可在執行時期跨越UnTrust Code所許可的記憶體執行範圍
查核原則會在程式啟動時進行,負責查核的這段程式會跟NaCl Trust Code Base(TCB) 整合在一起成為Native Client Run-Time System的一部分. x86 32bits的CFI方案會利用x86 Segment Registers作為執行階段的Sandbox效能改善的一部分.
在Paper ‘Efficient Software-Based Fault Isolation’中有介紹到兩種Software Fault Isolation的實作方式,分別為Segment Matching與Address Sandboxing, 筆者分別加以說明如下
1,Segment Matching (其實就是CFI的概念):可針對不安全的Store對記憶體寫入或與處理器Program Counter有關的Jump/Branch跳到新位址執行的指令進行靜態指令集查核,確保是在所設定的保護記憶體Segment內.靜態檢查只能針對寫入記憶體與跳過去執行指令時是採用預先定義好的記憶體資料或指令位址的寫法,若是把資料或指令所在的記憶體位址先寫入到暫存器,並且必須要經過一些運算得到最後所在的記憶體位址時,靜態檢查就無法在這狀況下提供如預期的效益. 因此,如果針對上述寫入記憶體與執行指令的動作前,先加入Checking Code,用以檢查最後所要去寫入或執行的記憶體位址是否超過目前模組所在的Fault Domain,若超過, 則針對這軟體模組觸發System Trap Error,這樣的技術就稱為Segment Matching.
在RISC架構下 (使用記憶體資料時,必須要透過Load/Store指令),Segment Matching支援一個記憶體查核的動作至少需要四個Dedicated Register 暫存器機制參與.
一個用來記錄Code Segment,一個記錄Data Segment,一個儲存Segment Shift Bits,一個儲存Segment Identifier.基於這樣的限制,也就必須要透過編譯器的支援,在產生UnTrust Module的編譯結果時,就必須要把希望避開的暫存器在編譯階段進行處理,並在效能上加以優化.
必須在所有UnTrust Module中都不可以使用到的暫存器,只限定給所插入的Check Coding中使用,若沒有這樣的限制,會有機會讓UnTrust Code跟Checking Code都使用到同樣的記憶體位址查核暫存器,且UnTrust Code也可以修改到這個暫存器,而導致防護上的遺漏.
一個基於這四個Dedicated Registers的Segment Matching稽核流程為
| 1,把所要寫入(Data)或產生Jump/Branch(Code)動作的Target Address 寫入Data/Code Dedicated Register
2, Data/Code Dedicated Register >> Segment-Shift Dedicated Register 的結果寫入任意可用的暫存器A中.
3,比對A是否符合 Segment-Identifier Dedicated Register
4,如果Target Address經過 Right-Shift 結果與 Segment-Identifier Dedicated Register 不符合,表示Target Address超過UnTrust Module所應該要寫入或執行的有效記憶體範圍外,如此則觸發System Error Trap以進行後續處理
5,如果比對後確認Target Address是在UnTrust Module有效寫入或執行的記憶體範圍內,就以Target Address所儲存在的Data/Code Dedicated Register進行後續寫入或執行所用位址暫存器.
|
Segment Matching優點在於能針對要防護的指令加以防範,能有效的降低軟體執行的Overhead. 除了基於Target Address在Right-Shift後與Segment Identifier比對Illegal Address的機制外,Address Sandboxing能提供不同的機制.
2,Address Sandboxing (其實就是SFI的概念):
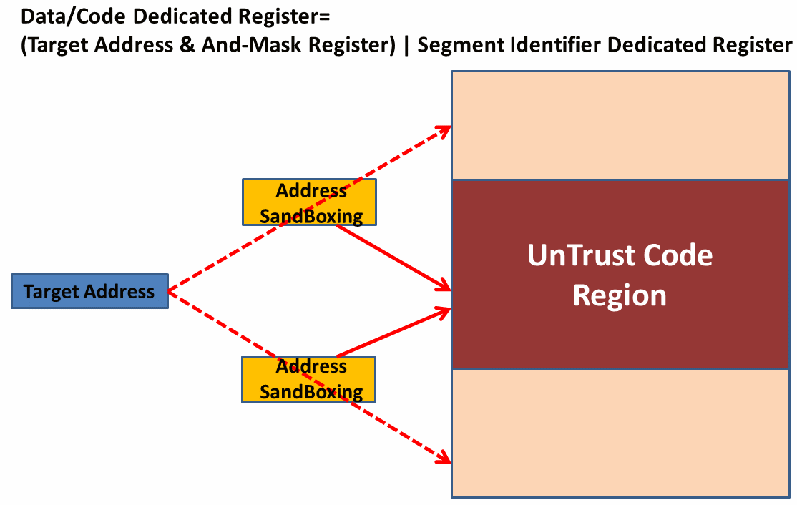
根據這篇論文的設計,Address SanBoxing會需要有五個Dedicated Registers (比Segment Matching多出一個),兩個用來儲存Code/Data Segment Identifier,一個儲存Segment And-Mask (用以作為 & 把Target Address Segment區塊給消掉),兩個用來儲存經過Sandbox處理後要去寫入或執行的Data/Code Address,如下圖所示
Data/Code Dedicated Register=
(Target Address & And-Mask Register) | Segment Identifier Dedicated Register
在CISC Fault Isolation之外,Software Fault Isolation(SFI)技術可解決CFI必須基於CISC 處理器支援的Code/Data Segment Register限制.雖然純軟體方案的SFI具備跨平台性,但每個處理器的指令集也有相當差異,以實際的測試來說,SFI 在ARM的Overhead會比x86更輕,有一部分原因在於CISC/RISC指令集的差異,例如ARM指令是32bits alignment(Thumb 是16bits alignment, Thumb2 則為 16/32bits alignment),而x86 CISC指令會有1 bytes到十幾bytes各種不等長的指令組合,如下所示
| (1bytes)0×48 = dec eax
(2bytes)0×89 F9= mov ecx,edi
(7bytes)0x8B BC 24 A4 01 00 00 = mov edi,dword ptr [esp+000001A4h]
(11bytes)0×81 BC 24 14 01 00 00 FF 00 00 00 = cmp dword ptr [esp+00000114h],0FFh
|
在unTrust Code 記憶體範圍內執行非直接記憶體的程式碼跳躍或是非直接的記憶體資料存取 (Indirect control flow and memory references),都會被Sandbox過濾,並以組合指令取代. SFI在x86上會基於MMU利用Page Protection,避免UnTrust Code有機會去影響到Trust Code.
在UnTrust Data的記憶體範圍,會在前後預留Guard Page,用以避免記憶體Overflow,Underflow與錯置記憶體的問題發生.為確保Source Code Level的可移植性, ARM/x86_64都跟x86_32平台一樣為 ILP32 (32-bits Int,Long and Pointer)的主要資料型別.就算NaCl是運作在64-bits環境下,也會限制NaCl應用只能使用32-bits 4GB的記憶體空間.
SFI (Software Fault Isolation)
要介紹SFI技術,最好的解釋方式應該是程式碼中會有Trust與UnTrust的Code,而這些Trust的Code主要是由平台提供者所撰寫的程式碼,UnTrust的Code則是平台開發者同意讓第三方軟件可以在該平台執行的程式碼,當今天平台提供者希望透過軟體的技術達到在不同處理器硬體上都可以實現保護Trust Code執行與偵測防範UnTrust Code的目的時,Software Fault Isolation技術也就因此誕生了.
SFI主要會包括以下的條件
1,在同一塊記憶體空間中,把UnTrust Code/Data搬到邏輯上劃分給UnTrust Code/Data的區域.
2,透過程式碼的查核,找出UnTrust Code中嘗試寫出或是跳出UnTrust Code所配置邏輯記憶體範圍的位置,並加入檢查機制的程式碼
SFI 整體概念如下圖所示,傳統上習知的Trust Code是Kernel Space,但在SFI技術下,同一個Process內部又可以劃分出屬於平台/Framework/Service的Trust Code與屬於第三方應用的UnTrust Code,彼此的交互呼叫則可透過SFI技術來實現.
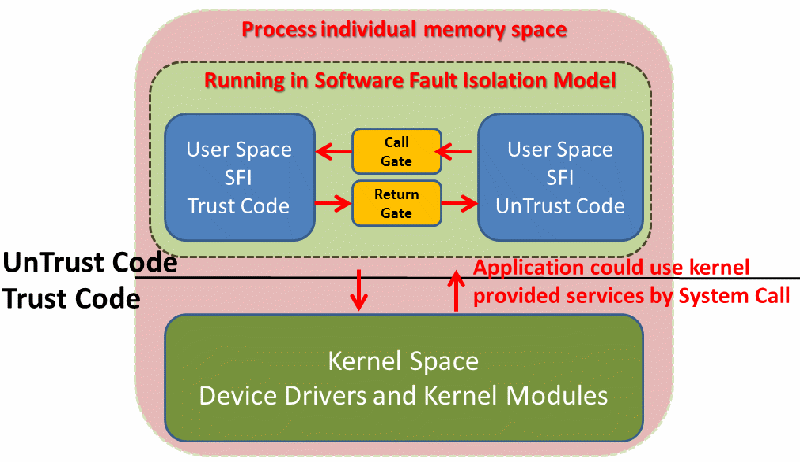
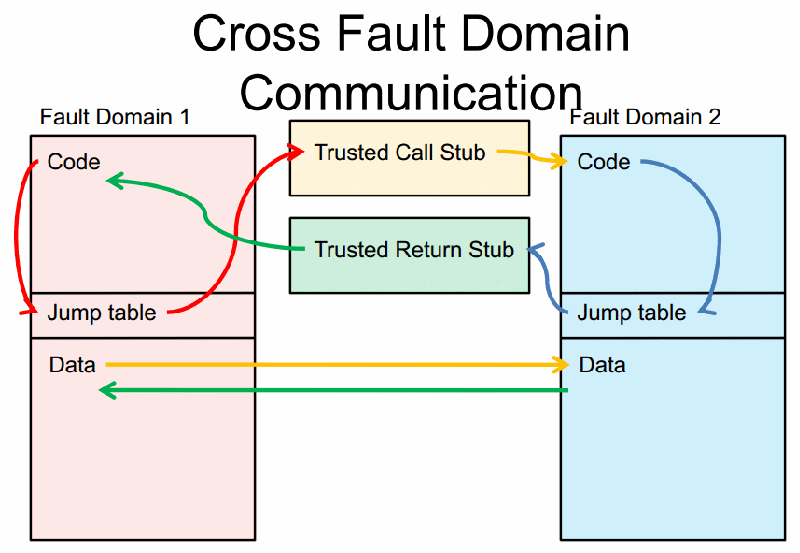
如下圖所示 (參閱自 Software Fault Isolation (at CS Language-Based Security,January 23, 2008)),在同一個UnTrust Code內的程式碼是可以彼此呼叫的,若是有跨Domain的呼叫時,透過Jump Table的機制讓函式的呼叫,函式的返回在跨Domain間都是間接的呼叫與返回,藉此可以透過 Trusted Call/Return Stub機制進行稽核的動作,而在Run-Time時,就可以去稽核程式碼,避免有跨出Jump Table以外的呼叫/返回可能.
接下來讓我們根據Google Native Client SFI的實現加以介紹.
NaCl SFI
Native Client主要基於Browser,讓Browser Based的應用應用能以原生應用程式效能運作的目的之用. 並提供Software Fault Isolation Run-Time的安全管理機制,讓應用程式可以呼叫所需的系統服務,但又不減損安全性.基於希望解決目前Browser-based Application的效率問題 (目前被廣泛應用的Browser-Based Application開發語言為Java Script),像是微軟所推出的ActiveX 或 NPAPI 以Browser Plug-in模組的方式提供Native Code層級的效能執行
基於此Native Client希望提供一個安全的框架,把基於網頁的原生碼應用程式Native Code分為兩個部分,
1,屬於Native Code受限的執行環境,以預防不合法的操作所帶來的副作用
2,屬於Host端提供的Run-Time Native Code安全執行環境,
可參考如下示意圖,一個網頁的應用程式,其中 HTML/JavaScript與該網頁上所提供的Native Client APP由於是透過網頁下載,會被定義為UnTrust 的程式碼,而本機所提供的Run-Time Framework包括後端的儲存機制,由於是基於本機所提供的服務,會被定義為Trust程式碼. 上層的HTML/JavaScript.
Native Client APP是具備可跨到不同平台與執行環境的能力 (基於底層Run-Time Framework的提供).
ActiveX最大的差別是,ActiveX是透過GUID與憑證去驗證該Native Code應用程式是否為可信賴的,若不具備可靠的憑證,就會跳出警告的對話盒讓使用者自行判斷 (雖然多數使用者並不具備判斷的能力),但Native Client是把稽核的工作交給NaCl container進行,也就是說使用者端並不會收到警告的對話盒.
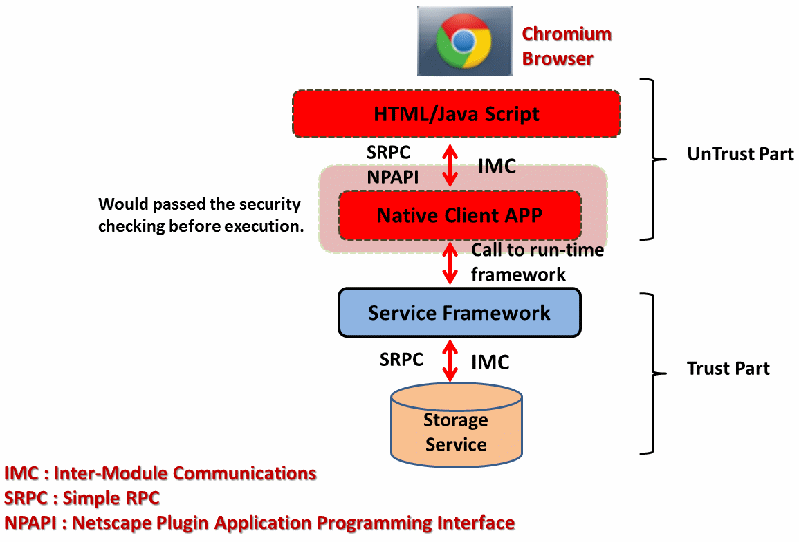
每個模組間都會在自己獨立的記憶體範圍內,跨模組的溝通會基於Native Client的IMC (Inter-Module Communications)機制,以上圖來說,HTML/JavaScript跟Native Client會透過Simple RPC或NPAPI(Netscape Plugin Application Programming Interface)溝通,而資料的傳遞則基於Shared Memory或Simple RPC的IMC機制來進行,一個應用程式所需基於 libc.so..etc的 Run-Time Framework(像是Memory/String/Storage/POSIX Thread interface, Mutexes, Semaphores..etc)有關的APIs,則由底層的Run-Time Framework提供,每個NaCl模組間的溝通也都必須要透過IMC,而不允許直接的資料傳遞,以避免可能的安全性問題.
一個Native Client能執行自己所在所驗證過的Code Segment,與透過NaCl API去使用Run-Time Service,並經由InterModule Communication Interface傳遞資料,亦可malloc記憶體與產生新的Thread (但不可產生新的Process.).在經過程式碼稽核後, Native Client App才得以繼續執行,
Native Client Run-Time
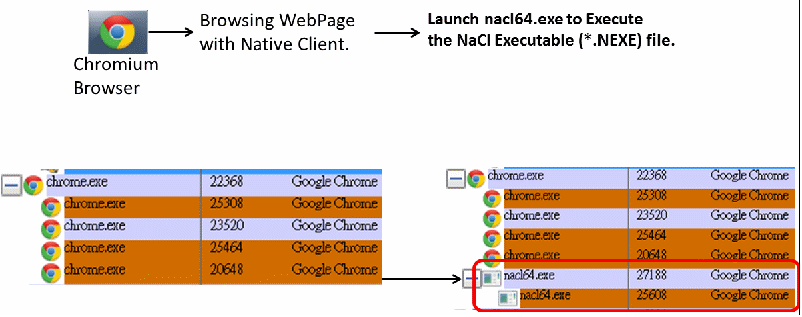
當瀏覽器要去下載一個Native Client網頁時,會把包括網頁內容與NaCl 執行檔.NEXE檔案下載到本機電腦來,如下圖所示, Chrome在下載.NEXE檔案後,以筆者的Windows 64bits電腦來說,會啟動nacl64.exe作為Native Client .NEXE執行檔的載入程式
而在下載的網頁內容中,會包括一個Link指到NMF檔案,這個NMF檔案會包含有關執行檔案.NEXE的MetaData,會包括這執行程式的Dynamic Linker .So與在執行過程中所需要用到的.So動態函式庫.
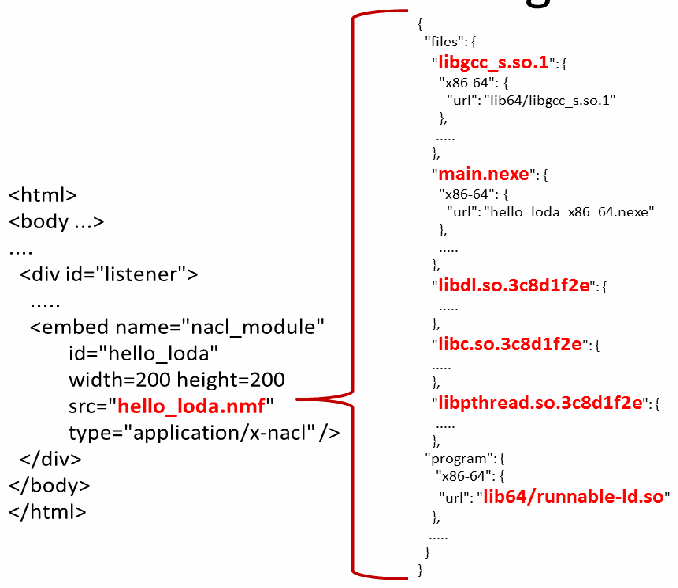
根據.NEXE的MetaData在Native Client啟動過程中,就會根據本機電腦的處理器資訊,例如筆者電腦為Windws 64bits就會下載hello_loda_x86_64.nexe NaCl執行檔,並會下載有關的.So,如下所示對應的檔案下載後,會儲存在使用者電腦的 AppData\Local\Temp下,以筆者驗證的環境為例,這些檔案會被Rename為不同的.Tmp檔案 (例如 6934.Tmp 其實就是libc.so.3c8d1f2e,而6901.Tmp其實就是 hello_loda_x86_64.nexe主執行檔.)
6934.Tmp (=libc.so.3c8d1f2e)
6922.Tmp (=libdl.so.3c8d1f2e)
6933.tmp (=libgcc_s.so.1)
6912.tmp (=libpthread.so.3c8d1f2e)
67D8.tmp (=runnable-ld.so)
66AE.tmp (=hello_loda.nmf)
6901.Tmp (= hello_loda_x86_64.nexe)
整體概念如下圖所示

如果把.NEXE執行檔,與所需的階層.So以彼此的Dependency 畫成階層關係圖,可以參考如下圖所示

其實在驗證的過程中,包括這些 .So檔案的下載其實都不小,例如 libc.so.3c8d1f2e約9.8MB,而runnable-ld.so約1.1MB,而這兩個卻又是一個Native Client執行環境的基本元素,以網路頻寬而言,實在覺得Native Client的執行成本似乎也太高了……@@@@
以技術而言,Native Client SFI SandBox真的是一個很棒的方案,但雖然Google已經為PNaCl預備了ARM的執行環境,但以所需下載的檔案成本而言,對以ARM為主的手持裝置(多數為手機),在這部份似乎還有很大的改善空間.
Native Client SandBox
Native Client的SandBox可以分為Inner SandBox(binary validation)與Outer SandBox (OS system-call interception),如下圖所示,其中 Inner Sandbox主要負責在編譯程式碼的過程中,透過靜態分析(static analysis) 屬於UnTrust區間的程式碼,確認沒有指令對合法記憶體位址外的寫入與執行動作,定義查核的Rules,針對Stack Pointer,函式呼叫,返回,與對記憶體的讀寫操作使用的記憶體位址進行稽核的程式碼產生.在x86平台上,還會利用Data與Code Segment Registrs的特性(這是ARM處理器上所沒有的),透過處理器硬體限制Data與Code的記憶體參考範圍,以降低對效能的影響.
但程式碼畢竟是在開發者的電腦上所產生的結果,如果開發者也理解inner sandbox對於這些操作程式碼的原理,其實還是有很大的機會被破解. 也因此在Run-Time過程也有一層outer sandbox機制,針對使用者透過內嵌Assembly,或透過二進位方式把執行碼植入的手段進行稽核,例如刻意在程式碼中加入直接對作業系統System Call呼叫的機制,在此就會被稽核,而導致程式無法正常執行.

基於Inner SandBox,一個x86 Native Client執行檔在執行指令上會有以下的限制
1,不能直接使用syscall 與int指令去呼叫作業系統提供的System Call
2,不能直接使用會影響到x86 Segment狀態的指令集,像是lds, far calls..
3,函式結束時,不會使用ret指令,而是會透過jmp藉由包裝過的機制,返回呼叫者
4,禁止所有需要特權等級的指令或 hlt指令.
5,不支援Hardware Exception ( Segment Fault,Floating Point Exception)與外部中斷的處理
6,支援 C+ 的exception,但不支援只有在Windows平台才支援的SEH (Structured Exception Handling)應用程式例外處理機制. (這機制在Windows以外平台並不支援.)
7,Native Client程式碼一旦載入到記憶體中,就會透過OS層級的保護機制,設定該區塊記憶體在執行時期為不可寫入的狀態. (在linux下可透過mprotect把記憶體設定為不可寫入)
8,會進行”control flow integrity”的查核,確保在程式碼執行的Flow中,所要前往執行記憶體位址所在的指令都是有效指令.
9,提供如下nacljmp的組合指令,進行程式碼的呼叫流程.在x86上的nacljmp實作如下所示,會確保所有指令的jump都是32bytes alignment
| X86_32:
and $0xffffffe0,%ecx
jmp *%ecx
|
| X86_64:
and $0xffffffffffffffe0,%r11d
add %r15,%r11
jmpq *%r11
|
10,程式碼的Validator會確保Data Integrity,沒有載入或寫出資料在許可記憶體範圍外的動作,要執行的代碼都是可以被反組譯的 (Reliable dis-assembly)
而Outer SandBox指的是應用程式在Run-Time執行時,透過作業系統System Call,或是刻意透過Run-Time Service漏洞來執行不合法行為的動態執行時期稽核機制.
x86_64 SFI Inner SandBox
參考Google文件,在x86_64與在ARM平台上提供SFI技術開發所遇到的問題多數的情況都很類似,只有在一些細節上會有很大的差異,例如: 在ARM平台上一個有效的Data Address前後會加上Guard Region,且ARM平台上的SFI是簡單以是否在1GB以下的範圍來區分是否為UnTrsut Code或Trust Code.
但在x86_86方案中就不是以如此簡單的方式來做區別.x86平台從32bits演進到64bits,在暫存器的使用命名有一個基礎上的變動,例如: AX 暫存器指的是16bits AX暫存器,而 EAX指的是32bits AX暫存器,而RAX指的是64bits AX暫存器.以及並在x86 bits環境下提供了八個新的通用暫存器 (General Purpose Registers).並透過修改 RSP(Stack Pointer)與 RBP (Base Pointer)來確保所要存取的Data Address都是在合法的記憶體範圍內.
x86_64環境並不像ARM一樣只用1GB記憶體以內為邊界來判定是否為UnTrust Memory,每個x86_64上的UnTrust Code應用程式會認為自己可以Access完整4GB的記憶體空間,但是在ARM上的UnTrust Code則認為自己只有0-1GB的有效記憶體空間可以被使用.
根據Google文件,x86_64 Native Client環境會遵循以下原則
1,UnTrust/Trust Module每個所配置到的記憶體空間都會跟4GB範圍對齊,並在前後各預留 10x4GB的記憶體空間,作為Protected/Unmapped Region
2,x86_64的r15暫存器,被定義為Designated Register RZP(Reserved Zero-address base Pointer),會被初始化指到一個4GB Aligned base address作為對應模組UnTrust Memory空間的起點,對UnTrust Code而言這個暫存器會是唯讀的
3,對RIP暫存器的寫入動作都會是 RZP的
為了確保 RSP/RBP 所包含的Stack Address都是有效的記憶體位址,會有以下的操作限制
1,RBP可以被修改,藉由從RSP以沒有Masking的方式進行拷貝動作
2,RSP可以被修改,藉由從RBP以沒有Masking的方式進行拷貝動作
3,其它對RSP/RBP暫存器的修改動作,則必須透過一組SFI虛擬指令進行,以便對目標記憶體位址進行Mask,確保目標記憶體位址是在合法的範圍內.
基於此,一個有效的RSP暫存器操作會以如下組合指令進行,
| 10001e0: 8b 2c 24 mov (%rsp),%ebp
10001e3: 4a 8d 6c 3d 00 lea 0x0(%rbp,%r15,1),%rbp
10001e8: 83 c4 08 add $0x8,%esp
10001eb: 4a 8d 24 3c lea (%rsp,%r15,1),%rsp
|
例如,add $0x8,%esp 就可以確保RSP 64bits長度的內容,最高的32bits會被Clear,以便ESP會限制在所許可的32bits範圍內.而R15會等於目前這個SFI Native Client所被允許的64-bits位元內所配備置的32-bits 4GB範圍.由於限制了RSP必須在有效的4GB範圍內,因此像是對暫存器操作的Push/Pop或 near call指令就可省去額外的確保動作.
有關RSP暫存器的操作與 GCC跟pnacl-clang兩者編譯後結果的比較,可以參考如下圖所示

可以看到函式的入口一定會是32bytes Alignment,且會把64bits RSP 高位址32-bits給清掉,並基於x86_64上的R15暫存器來限制RSP應用在指定的64bits 的 32-bits 4GB記憶體範圍內.
有關函式呼叫的動作,如下所示同樣以 GCC跟pnacl-clang兩者編譯後結果的比較,可以看到若基於Function Pointer呼叫時,若以RAX暫存器為最後函式呼叫的位址,在正式呼叫前會先透過 and 確認eax一定是32byte Alignment且高位址的32bits會清為0,最後同樣會透過x86_64上的R15暫存器來限制RAX在指定的64bits 的 32-bits 4GB記憶體範圍內.

有關函式呼叫的動作,如下所示同樣以 GCC跟pnacl-clang兩者編譯後結果的比較,可以看到若基於Fnction PLT (Procedure Linkage Table)呼叫時,會把PLT Table呼叫入口置入一組程式碼,並藉此確保R11暫存器函式呼叫的位址,在正式呼叫前會先透過 and 確認R11一定是32byte Alignment且高位址的32bits會清為0,最後同樣會透過x86_64上的R15暫存器來限制R11在指定的64bits 的 32-bits 4GB記憶體範圍內.

有關函式呼叫的動作,如下所示同樣以 GCC跟pnacl-clang兩者編譯後結果的比較,可以看到若是在UnTrust Code範圍內的呼叫,就會直接呼叫而無需再透過額外的查核動作.

在記憶體讀寫的操作上,最常見的記憶體位址處理方式為把一個有效的Base Address Register (RSP/RBP或RZP (在這為R15))跟 32-bits Displacement數值進行處理,用32-bits值取代,加上一個32-bits index與一個Scaling Factor,有關的計算邏輯可以參考下面的算式
basereg + indexreg * scale + disp32
例如如下虛擬程式碼
add $0x00abcdef, %ecx
mov %eax, disp32(%RZP, %rcx, scale)
舉下述實際的記憶體讀寫操作範例來看,包括在對記憶體寫入與讀取操作時,就會透過 像是 ‘mov 0x22(%r15,%rax,1),%al’ 以 ‘basereg + indexreg * scale + disp32’來對記憶體作讀取或寫入,並以R15限定最後存取的記憶體位址是在指定的64bits 的 32-bits 4GB記憶體範圍內.
有關x86_64的Function Return操作,如果以RDX暫存器進行程式碼記憶體位址的跳過流程控制的話,就可以下述參考的虛擬程式碼來進行
%edx = …
and 0xffffffe0, %edx
lea (%RZP, %rdx, 1), %rdx
jmp *%rdx
舉下述實際的記憶體讀寫操作範例來看,會以RCX確認RCX一定是32byte Alignment且高位址的32bits會清為0,最後同樣會透過x86_64上的R15暫存器來限制RCX在指定的64bits 的 32-bits 4GB記憶體範圍內,以便最後Function Return時一定是在所許可的記憶體範圍內.

基於上述的解說,我把x86_64環境下,每個Native Client所用有的4GB Memory Space的概念用下圖表示,我們可以知道透過SFI SandBox機制確保,可以讓在x86_64環境執行的應用能擁有獨立的4GB空間,並會透過R15與64bits暫存器的操作,確保不會被預期外的高位址32-bits操作,導致有溢出4GB記憶體空間的不合法執行行為存在.

ARM SFI Inner SandBox
以ARM CortexA9 1GHz方案來說,參考Google文件,在啟動SFI機制後,增加約5%的CPU Overhead與20%的檔案大小,其中包括10%的Padding到16 bytes Alignment的成本,而10%為針對非直接的記憶體寫入與非直接的程式碼執行路徑所加入的檢查程式碼. (以上的比率, 都會隨著不同應用程式的實作方式差異,導致SandBox處理結果不同,而有所改變).
在ARM平台上,SFI目前只支援ARMv32而不支援有 Thumb 16bits 或Thumb2 16/32bits並存的指令. 這是基於SFI主要考量的是效率而非Code Density.
如下圖所示,在ARM SFI下,0-1GB是UnTrust Store/Control Flow memory space,在1GB-4GB這3GB範圍是屬於 Trust Run-Time與作業系統區.但在x86_64上,並不限制UnTrust Code讀取1GB以外的記憶體 (但不能溢出SandBox所指定的範圍.),在ARM平台上會,SFI會包括
1,確保所有的UnTrust Code不能執行任何被禁止的指令. (Undefine Instruction,Ram System Call)
2,確保UnTrust Code不能寫入與執行1GB以上記憶體的資料與程式碼
3,確保UnTrust Code不能Jump到1GB以上的記憶體位址

ARM上的實作,SFI SandBox記憶體操作可在一個指令中完成,不需像其它平台的實作要有額外的暫存器 (所以ARM的R0-R15都可以被使用.)
ARM版本跟x86支援指令不同之處在於ARMv32支援固定32-bits指令,會以每16bytes Alignment (四個ARMv32指令)長度進行處理.非直接程式碼/資料存取的Control Flow會以每個16bytes的bundle為單位.由於ARM Code的區塊也會Embedded 部分 Data with Code Segment,為避免該區域有機會導致程式流程跑過去執行的問題,在會Data Bundles的起點位址加入一個無效指令集.(bkpt 0x7777)去避免執行到這部份的Data.
如果執行到一個直接的Branch(記憶體位址直接指定),就會直接確認所Branch過去的記憶體位址所在是否為一個有效的指令.而對非直接的Branch(記憶體位址需要經過額外的計算處理,最後才透過ARM Program Counter (=r15)進行執行Branch的跳躍).
We forbid most of these instructions2 and consider only explicit branch-to-address-in-register forms such as bx r0 and their conditional equivalents.
針對要跳躍過去的記憶體位址可以透過ARM Bit Clear (bic) 指令進行處理,限制UnTrust Code可以在1GB以下低位址區域中執行.如下為一個透過 r1 的 SandBox Branch虛擬指令.可用以確保在ARM上Branch的位址必須是在1GB以內,並且每個Branch過去執行的程式碼記憶體位址都是16bytes alignment.
| 1e8: e3c1113f bic r1, r1, #-1073741809 ; 0xc000000f
1ec: e12fff31 blx r1
|
舉下述實際的操作範例來看,這是一個在ARM上取Function Pointer到變數f1後,跳過去執行的例子,其中會透過bic (Bit Clear)指令確保R1一定是16byte Alignment且在1GB記憶體位址以下所許可的記憶體範圍內.

基於安全性的考慮,一般ARMv32會使用的pop {pc}寫法是不被允許的,以免被故意塞入惡意的返回位址,讓ARM SFI SandBox函式返回時形成安全漏洞.會先把要返回的位址儲存在LR中,經過Bit Clear指令確保返回位址是在1GB以下且16bytes alignment,才進行Branch操作,可參考如下範例程式
| 210: e28dd010 add sp, sp, #16
214: e3cdd103 bic sp, sp, #-1073741824 ; 0xc0000000
218: e8bd4800 pop {fp, lr}
21c: e320f000 nop {0}
220: e3cee13f bic lr, lr, #-1073741809 ; 0xc000000f
224: e12fff1e bx lr
|
(LR 是一般ARM處理器上用來記錄返回位址的暫存器),
舉下述實際的操作範例來看,這是一個在ARM上Function 執行結束後準備返回的例子,其中會透過bic (Bit Clear)指令確保LR一定是16byte Alignment且在1GB記憶體位址以下所許可的記憶體範圍內.

在記憶體寫入的動作上,會確認要寫入的記憶體位址是小於1GB,並且寫入的記憶體位只是沒有Memory Alignment的限制.以目前的實作會透過ARM test指令來做確認,如下參考程式碼
tst r0, #0xc0000000
streq r1, [r0, #12]
就像是Bit Clear,Test指令會檢測所要寫入的記憶體位址(而且不會修改r0中的內容),如果確定是小於1GB 就會在下一個ARMv32 Condition指令決定是否要讓 Store動作可以真的把資料寫入到目標記憶體位址中.
舉下述記憶體讀寫實際的操作範例來看,這是一個在ARM上透過R0取得最後讀寫記憶體位址的例子,其中會透過bic (Bit Clear)指令確保R0一定是在1GB記憶體位址以下所許可的記憶體範圍內.(記憶體的讀寫就不用確保16 bytes Alignment了.)

對儲存在Stack中的區域變數寫入資料,是程式執行過程中經常會遇到的情況.也因此針對Stack Pointer所指位址寫入與判斷這個Stack Pointer是否指向一個有效的Data Address (通常 Process Stack Address都會落在高位址),會是ARM SFI需要直接面對到的問題,也因此會在UnTrusted Progeam初始化時確認SP是一個有效的記憶體位址(小於1GB),如果透過指令自行更新Stack Pointer,若該記憶體位址為無效位址,就會產生一個Fault,若指令有直接更新SP暫存器的動作,就會被SandBox以以下的指令進行修正,
mov SP, r1
bic SP, SP, #c0000000
舉下述實際的操作範例來看,這是一個在ARM上Function 的進入點,其中會透過bic (Bit Clear)指令確保SP一定是在1GB記憶體位址以下所許可的記憶體範圍內.

介紹至此,我們應該已經把x86 64 bits與ARM這兩個常見平台的Sandbox與實際產生的Machine Code作了說明,接下來讓我們稍微在比較一下其它類型的方案以及SDK上實際的操作演示.
User-ID based Access Control
Linux Kernel原本就會根據不同使用者的帳號去進行權限的保護措施,例如要去mount一個device,去修改不同帳號所屬的檔案,或是必須要有 root 權限才可以執行的部分System Call呼叫,都會被Linux Kernel基於使用者帳號所管理的安全機制所管控.
傳統的Windows使用者行為是一個使用者帳號登入後,會用這個使用者帳號安全多個應用程式,每個應用程式的權限都一樣,相對的如果我是一個惡意程式的開發者,既然這些眾多已經安裝的應用程式都是在同一個使用者權限下所安裝的 (更何況該使用者可能是用Local Administrator權限登入的),惡意程式就可以在所被賦予的權限範圍內去修改所要修改的檔案或是去植入所要植入的必要動作.
Android上的應用程式安全管理機制,正是充分發揮Linux Kernel根據不同使用者帳號權限管理機制,會讓每個所安裝的應用程式都會在所對應的App User Id中執行,也就是說要跨到另一個APP所屬的檔案或執行空間時,就會等於是要跨到另一個Linux Kernel User Id權限空間內,而Linux原本在不同使用者權限管理的措施上就已經是很穩固的基礎,Android把APP User Id跟Linux Kernel不同帳號管理機制綁定在一起,就可以確保每個Android應用程式如果要去修改其他Android應用程式時 (等於是另一個User Id權限),所要突破的門檻就會相對更高. 若在Android下有跨Process的IPC需求時,則可以另外透過像是Binder,自行產生的Socket…etc,其他機制來達成.
Trust with Authentication
在Native Client技術之前,微軟的ActiveX技術應該是讓網頁執行Native Code最著名的作法,但ActiveX Control主要的問題在於這是一個基於認證憑證的信賴關係,只要ActiveX取得微軟的憑證,就可以在不警告使用者的前提下,進行安裝.但一旦該應用程式被安裝到使用者電腦後,該網頁應用程式幾乎就等同於一般應用程式一樣,可以進行檔案讀寫與相關的網路通訊.
,但以網頁內嵌的ActiveX元件來說,在筆者的IE9上安裝時會出現以下的警告訊息,也因為這樣的警告訊息,對多數使用者而言,其實也不知道所按下的 ‘允許’ 是同意了怎樣的Native Code應用程式在本機執行,但又基於這些警告的對話盒訊息,會讓一般使用者普遍認知從網頁上下載的原生碼應用程式是不安全的認知.

以往,要解決這樣的問題通常會把要讓使用者安全的ActiveX元件,先透過Setup安裝包的方式,讓使用者先安裝到自己電腦上,而當瀏覽同樣的網頁,遇到要載入指定的GUID ActiveX元件時,就會因為該GUID所對應的ActiveX元件已經被安裝在本機電腦上,而非經由網頁傳遞下來的,就可以避免這樣的警告訊息.
Native Client SDK與 Source Code下載
就跟Android開發環境一樣,開發者可以選擇自己是要基於SDK的應用程式開發或是要取得SDK Source進行深度的開發工作,同樣的需求,在Native Client中也是如此.
SDK的下載工具為 naclsdk (可以參考網頁https://developers.google.com/native-client/sdk/download),可透過指令naclsdk update下載NaCl SDK版本,與透過naclsdk list檢視目前已經下載的版本.
NaCl Source Code的下載工具為gclient,若只是PNaCl應用程式的開發者,可以直接下載Native Client開發SDK可至 https://developers.google.com/native-client/sdk/download ,下載已經編譯好的NaCl SDK環境(依據SDK差異會有不同pepper版本號碼),ToolChain與NaCl Application範例程式.
PnaCl Source Code環境可以透過gclient工具下載.在編譯PNaCl前,可以先到http://dev.chromium.org/developers/how-tos/install-depot-tools ,根據開發所在的環境,下載depot_tools工具包,其中就會包括 gclient.
| 同步工具 | 說明 |
| naclsdk | 用以下載編譯好的(Portable) Native Client SDK開發環境,適合一般(Portable) Native Client 應用程式開發者. |
| gclient | 用以下載(Portable) Native Client Source Code,適合要對Native Client技術有深入探索的開發者. |
編譯第一個PNaCl程式
透過
gclient config http://src.chromium.org/native_client/trunk/src/native_client
gclient sync
下載完整Native Client與Portable Native Client Source Code後,需先編譯函式庫與Pepper API header檔案,以筆者環境來說,可先至 ‘/home/loda/nacl/native_client’ 目錄下執行
pnacl/build.sh sdk newlib
pnacl/build.sh ppapi-headers
即可完成編譯.
不同於一般常用的make編譯環境,Native Client所採用的 Build 環境為Hammer (http://code.google.com/p/swtoolkit/ ),這是一個基於 SCons (http://www.scons.org/)的延伸Build環境, SCons是一個Open Source,基於Python的跨平台編譯環境設定建置的工具,可用以取代一般使用的make. 有關SCons and Hammer編譯環境資訊可參考 http://code.google.com/p/chromium/wiki/ChromiumSoftwareConstructionSystem 與 Building and Testing the Native Client Trusted Code Base(http://www.chromium.org/nativeclient/how-tos/build-tcb ).
在PNaCl架構下,基於LLVM執行檔可以分為以下三類
| 檔案格式 | 說明 |
| .bc | Bitcode object file. (Analogous to a plain object file) |
| .pexe | Bitcode executable. (Analogous to an executable file) |
| .pso | Bitcode shared object. (Analogous to a shared object file) |
除了一般BinUtiles的工具,像是pnacl-clang/clang++/ld/ar/nm/ranlib/strip/as,同時PNaCl還提供pnacl-translate可用以把PNaCl BitCode反組譯回Native Code.
以筆者透過gclient所下載的Source Code環境來說,可以在native_client目錄下找到對應到筆者開發環境的Linux x86_64 pnacl 開發工具 (建議可以把檔案搜尋路徑設置過來.)
| [root@www bin]# pwd
/home/loda/nacl/native_client/toolchain/pnacl_linux_x86_64/glibc/bin
[root@www bin]# ls
driver.conf pnacl-as pnacl-dis pnacl-ld pnacl-nativeld pnacl-nop pnacl-readelf pydir wrapper-link-and-translate
findpython.sh pnacl-clang pnacl-driver pnacl-meta pnacl-nm pnacl-opt pnacl-strip readelf
pnacl-ar pnacl-clang++ pnacl-illegal pnacl-meta-unpack pnacl-nmf pnacl-ranlib pnacl-translate size
[root@www bin]#
|
接下來讓我們以實際的例子驗證PNaCl執行檔,以如下的範例程式來說
| #include <stdio.h>
#include <stdlib.h>
int main()
{
printf(“loda PNaCl test!\n”);
//write(1,”222″,4);
return 0;
}
|
執行如下命令進行編譯
pnacl-clang hello.c -o hello.pexe
再把.pexe (BitCode)轉成.nexe(Native Code)
pnacl-translate -arch x86-64 hello.pexe -o hello64.nexe
就跟在 SDK中開發一樣, .nexe檔案的執行會需要透過有支援NaCl的瀏覽器執行環境,或是透過專屬的Run-Time工具,若我們直接在執行剛才編譯出來的執行檔,會看到如下的錯誤訊息
| ./hello64.nexe
-bash: ./hello64.nexe: ld-nacl-x86-32.so.1: bad ELF interpreter: No such file or directory
|
當然如果是希望透過瀏覽器執行,還是可以回到SDK環境中編譯把對應的Pepper版本與函式庫關係編譯到.nexe檔案格式中,但在Source Code Package中,有支援 run.py 可以不需額外透過瀏覽器,就能驗證程式開發的執行結果,如下所示
| run.py hello64.nexe
********************************************************************************
hello64.nexe is X86-64 DYNAMIC
********************************************************************************
/home/sena/nacl/native_client/scons-out/opt-linux-x86-64/staging/nacl_helper_bootstrap /home/sena/nacl/native_client/scons-out/opt-linux-x86-64/staging/sel_ldr -B /home/sena/nacl/native_client/scons-out/nacl_irt-x86-64/staging/irt.nexe -S -a — /home/sena/nacl/native_client/toolchain/linux_x86/x86_64-nacl/lib/runnable-ld.so –library-path /home/sena/nacl/native_client/toolchain/linux_x86/x86_64-nacl/lib /home/loda/LLVM/hello64.nexe
DEBUG MODE ENABLED (bypass acl)
[3877,3328583488:06:47:07.577028] BYPASSING ALL ACL CHECKS
[3877,3328583488:06:47:07.591525] Native Client module will be loaded at base address 0x00007f7700000000
[3877,3328370432:06:47:07.682474] NaClHostDescOpen: open returned -1, errno 2
loda PNaCl test!
|
檢視pnacl-clang所產生的BitCode
如果要檢視所產生的.PEXE BitCode執行檔MetaData內容,可以透過pnacl-nmf 工具來操作,如下所示
pnacl-nmf hello.pexe
可以產生如下的PNaCl BitCode MetaData內容,
| {
“files”: {
“ld-nacl-x86-32.so.1″: {
“arm”: {
“url”: “lib-arm/ld-nacl-x86-32.so.1″
},
“x86-32″: {
“url”: “lib-x86-32/ld-nacl-x86-32.so.1″
},
“x86-64″: {
“url”: “lib-x86-64/ld-nacl-x86-32.so.1″
}
},
“ld-nacl-x86-64.so.1″: {
“arm”: {
“url”: “lib-arm/ld-nacl-x86-64.so.1″
},
“x86-32″: {
“url”: “lib-x86-32/ld-nacl-x86-64.so.1″
},
“x86-64″: {
“url”: “lib-x86-64/ld-nacl-x86-64.so.1″
}
},
“libc.so.c4697f70″: {
“portable”: {
“pnacl-translate”: {
“sha256″: “f4461ca0596a8eb5f51b1bedfe293a4490b03277f3e8530988a17a431964081b”,
“url”: “libc.so.c4697f70″
}
}
},
“libgcc_s.so.1″: {
“arm”: {
“url”: “lib-arm/libgcc_s.so.1″
},
“x86-32″: {
“url”: “lib-x86-32/libgcc_s.so.1″
},
“x86-64″: {
“url”: “lib-x86-64/libgcc_s.so.1″
}
},
“main.nexe”: {
“portable”: {
“pnacl-translate”: {
“sha256″: “16ff8742c8aa59ae918177b6bb1c9548f2479fa8033442d9089ca10c161c7d23″,
“url”: “hello.pexe”
}
}
}
},
“program”: {
“arm”: {
“url”: “lib-arm/runnable-ld.so”
},
“x86-32″: {
“url”: “lib-x86-32/runnable-ld.so”
},
“x86-64″: {
“url”: “lib-x86-64/runnable-ld.so”
}
}
|
再透過pnacl-dis反組譯 hello.pexe內容
| ; ModuleID = ‘hello.pexe’
target datalayout = “e-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:64:64-f32:32:32-f64:64:64-p:32:32:32-v128:32:32″
target triple = “armv7-none-linux-gnueabi”
deplibs = [ “ld-nacl-x86-32.so.1″, “libc.so.c4697f70″ ]
@_IO_stdin_used = internal constant i32 131073, align 4
@llvm.used = appending global [1 x i8*] [i8* bitcast (void ()* @__crtbegin_dummy to i8*)], section “llvm.metadata”
@__dso_handle = internal global i8* null, align 4
@llvm.global_dtors = appending global [1 x { i32, void ()* }] [{ i32, void ()* } { i32 65535, void ()* @__do_global_dtors_aux }]
@.str = private unnamed_addr constant [18 x i8] c”loda PNaCl test!\0A\00″, align 1
@llvm.compiler.used = appending global [0 x i8*] zeroinitializer, section “llvm.metadata”
define void @_start(i32* %info) nounwind {
entry:
%info.addr = alloca i32*, align 4
%rtld_fini = alloca void ()*, align 4
%argc = alloca i32, align 4
%argv = alloca i8**, align 4
store i32* %info, i32** %info.addr, align 4
%0 = load i32** %info.addr, align 4
%arrayidx = getelementptr inbounds i32* %0, i32 0
%1 = load i32* %arrayidx, align 4
%2 = inttoptr i32 %1 to void ()*
store void ()* %2, void ()** %rtld_fini, align 4
%3 = load i32** %info.addr, align 4
%arrayidx1 = getelementptr inbounds i32* %3, i32 2
%4 = load i32* %arrayidx1, align 4
store i32 %4, i32* %argc, align 4
%5 = load i32** %info.addr, align 4
%arrayidx2 = getelementptr inbounds i32* %5, i32 3
%6 = bitcast i32* %arrayidx2 to i8*
%7 = bitcast i8* %6 to i8**
store i8** %7, i8*** %argv, align 4
%8 = load i32* %argc, align 4
%9 = load i8*** %argv, align 4
%10 = load void ()** %rtld_fini, align 4
%11 = call i8* @llvm.frameaddress(i32 0)
call void @__libc_start_main(i32 (i32, i8**, i8**)* bitcast (i32 ()* @main to i32 (i32, i8**, i8**)*), i32 %8, i8** %9, i32 (i32, i8**, i8**)* @__libc_csu_init, void ()* @__libc_csu_fini, void ()* %10, i8* %11)
br label %while.body
while.body: ; preds = %while.body, %entry
%12 = load volatile i32* null, align 4
br label %while.body
return: ; No predecessors!
ret void
}
declare void @__libc_start_main(i32 (i32, i8**, i8**)*, i32, i8**, i32 (i32, i8**, i8**)*, void ()*, void ()*, i8*)
declare i32 @__libc_csu_init(i32, i8**, i8**)
declare void @__libc_csu_fini()
declare i8* @llvm.frameaddress(i32) nounwind readnone
define void @_init() nounwind {
entry:
ret void
}
define internal void @_fini() nounwind {
entry:
ret void
}
define internal void @__crtbegin_dummy() nounwind {
entry:
call void @__do_global_dtors_aux()
store i8* null, i8** @__dso_handle, align 4
ret void
}
define internal void @__do_global_dtors_aux() nounwind {
entry:
ret void
}
define internal i32 @main() nounwind {
entry:
%retval = alloca i32, align 4
store i32 0, i32* %retval
%call = call i32 (i8*, …)* @printf(i8* getelementptr inbounds ([18 x i8]* @.str, i32 0, i32 0))
ret i32 0
}
declare i32 @printf(i8*, …)
!NeededRecord_libc.so.c4697f70 = !{!0, !1}
!OutputFormat = !{!2}
!0 = metadata !{metadata !”__libc_start_main”}
!1 = metadata !{metadata !”printf”}
!2 = metadata !{metadata !”executable”}
|
檢視pnacl-translate NaCl所產生的Machine Code.
.PEXE執行檔可透過pnacl-translate轉成指定平台的Native Code執行檔,針對所產生的執行檔內容可透過pnacl-dis進行反組譯,操作如下所示
pnacl-dis hello64.nexe
產生的反組譯內容如下所示 ()
| ………….
0000000001000300 <main>:
1000300: 55 push %rbp
1000301: 48 89 e5 mov %rsp,%rbp
1000304: 83 ec 10 sub $0x10,%esp
1000307: 4a 8d 24 3c lea (%rsp,%r15,1),%rsp
100030b: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
1000312: bf 5c 02 00 11 mov $0x1100025c,%edi
1000317: 30 c0 xor %al,%al
1000319: 66 90 xchg %ax,%ax
100031b: e8 e0 fd ff ff callq 1000100 <printf@plt+0xc0>
1000320: 31 c0 xor %eax,%eax
1000322: 83 c4 10 add $0x10,%esp
1000325: 4a 8d 24 3c lea (%rsp,%r15,1),%rsp
1000329: 8b 2c 24 mov (%rsp),%ebp
100032c: 4a 8d 6c 3d 00 lea 0x0(%rbp,%r15,1),%rbp
1000331: 83 c4 08 add $0x8,%esp
1000334: 4a 8d 24 3c lea (%rsp,%r15,1),%rsp
1000338: 59 pop %rcx
1000339: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
1000340: 83 e1 e0 and $0xffffffe0,%ecx
1000343: 4c 01 f9 add %r15,%rcx
1000346: ff e1 jmpq *%rcx
1000348: 66 66 66 66 66 66 2e data32 data32 data32 data32 data32 nopw %cs:0x0(%rax,%rax,1)
100034f: 0f 1f 84 00 00 00 00
1000356: 00
1000357: 90 nop
1000358: 90 nop
1000359: 90 nop
100035a: 90 nop
100035b: 90 nop
100035c: 90 nop
100035d: 90 nop
100035e: 90 nop
100035f: 90 nop
…..
|
結語
Native Client能否普及仍待持續觀察,但這技術基於LLVM所帶來的創新思維,其實會讓深入探究其中的我們得到很多收穫,希望對於閱讀本文的各位也有一樣的獲益.
分享這段很棒的話語 ‘懷疑能把昨天的信仰摧毀,也能替明日的信仰開路‘ by 羅曼‧羅蘭, 每當新的技術誕生時,基於已經習知的知識背景,我們通常都會有先入為主的評價,當事後探究相關的技術細節,其實收穫最多的還是我們自己.
Google的Native Client SFI 技術,可以讓原本大家認為不安全的遠端瀏覽器下載Native Code的行為,有了一個全新的視野,Native Code不是原本認為的不受限制,只要有機會運作,就可以透過作業系統的System Call或利用組語機械碼去跳脫被限制呼叫的函式庫,而是會進入Native Client SFI機制所設計的Sandbox中,去阻擋各種非經許可的行為與機械碼的操作動作.更重要的是,不同於以往要透過User/Kernel Space以處理器特權等級作保護的機制,上述的SFI Sandbox都是在User Space這層級完成的.當然,這也代表了背後更多種無限的遐想與可能. (玩破解的朋友們,這又多了一個好題目!!!)








0 意見:
張貼留言